A quick introduction to DDD
by libai8723
DDD
为什么又开始看DDD了呢,是因为最近有一个DDD的培训。领导说你都看过书了,就不用去了,但是仔细回想一下,基本仅仅是把DDD的书看完了Part 1,而且感觉似懂非懂,所以赶紧看一下。
在刷手机的时候看到了一篇关于DDD的简介的文章还是不错的:
为了让记忆更加深刻一点,还是简单写一写笔记和日志吧。
The philosophy of domain-driven design (DDD) - first described by Eric Evans in his book of the same name - is about placing our attention at the heart of the application, focusing on the complexity that is intrinsic to the business domain itself. We also distinguish the core domain (unique to the business) from the supporting sub-domains (typically generic in nature, such as money or time), and place appropriately more of our design efforts on the core.
DDD的哲学是把我们的最大的注意力放在应用的核心上,关注业务领域本身的固有的(intrinsic)复杂性。我们要能区分核心的领域和支撑性的子领域的区别。支撑性的子领域通常都是一些通用的领域,例如时间与金钱的领域。而我们要做的事情是把尽可能多一些的时间和精力放在core domain上。
关于代码和模型 Of Code and Models
With DDD we’re looking to create models of a problem domain. The persistence, user interfaces and messaging stuff can come later, it’s the domain that needs to be understood, because that’s the bit in the system being built that distinguishes your company’s business from your competitors. (And if that isn’t true, then consider buying a packaged product instead).
使用DDD的方法,我们试图寻找了一个问题领域的模型。而关于技术开发中的持久化,UI,消息传递机制,我们后面再谈。因为核心的问题是理解领域的知识。那才是我们的系统有别于其他人系统的核心点。
By model we don’t mean a diagram or set of diagrams; sure, diagrams are useful but they aren’t the model, just different views of the model (see Figure). No, the model is the set of concepts that we select to be implemented in software, represented in code and any other software artifact used to construct the delivered system. In other words, the code is the model. Text editors provide one way to work with this model, though modern tools provide plenty of other visualizations too
说到模型,我们不是说一个或者几个示意图就是一个模型。当然,示意图非常的有用,但是它们本身并不是模型,仅仅是关于model的不同的view,作者给了一个例子很生动:
模型是我们选择出来的用来在软件中实现的一系列的概念,我们使用代码或者其他的artifact来构建这个需要被交付的系统。换句话说。code就是模型。
This then is the first of the DDD patterns: a model-driven design. It means being able to map - ideally quite literally - the concepts in the model to those of the design/code. A change in the model implies a change to the code; changing the code means the model has changed. DDD doesn’t mandate that you model the domain using object-orientation - we could build models using a rules engine, for example - but given that the dominant enterprise programming languages are OO based, most models will be OO in nature. After all, OO is based on a modelling paradigm. The concepts of the model will be represented as classes and interfaces, the responsibilities as class members.
然后我们就讲到了DDD中的第一个设计模式:model-driven design,就是字面的意思。这个设计模式本身的意思就是模型和code是相互mapping的关系。如果模型发生了变化,那么code也要变化。
Speaking the Language
Let’s now look at another bedrock principle of domain-driven design. To recap: we want to build a domain model that captures the problem domain of the system being built, and we’re going to express that understanding in code / software artifacts. To help us do that, DDD advocates that the domain experts and developers consciously communicate using the concepts within the model. So the domain experts don’t describe a new user story in terms of a field on a screen or a menu item, they talk about the underlying property or behaviour that’s required on a domain object. Similarly the developers don’t talk about new instance variables of a class or columns in a database table.
然后我们提到了DDD中的基石的原理,所谓的ubiquitous language。 我们希望构建出一个领域模型,模型可以抓住问题领域中的主要的问题,并且我们将会使用代码或者软件制品来表达我们对问题的理解。为了帮助我们做到这一点,DDD拥护一种行为,让领域专家和开发人员,有意识的使用模型中的概念来进行交流。
以至于我们的领域专家不需要使用“屏幕上的一个字段”或者“目录中的一个选项”来描述一个新的User Story,让领域专家来谈对于一个领域对象来说,它应该具有什么样的属性和行为。
同样的,我们的开发人员也不会说,我们要创建一个新的类的实例或者是在数据表中新增一列。
Doing this rigorously we get to develop a ubiquitous language. If an idea can’t easily be expressed then it indicates a concept that’s missing from the domain model and the team work together to figure out what that missing concept is. Once this has been established then the new field on the screen or column in the database table follows on from that.
通过严格的遵守这样一种沟通的模式,我们将会开发出一种ubiquitous language。如果一个idea不能被简单的表达,那说明我们的领域模型中仍然缺少一些概念,我们需要团队协作来找出缺少的概念。并最终实现这个概念。
Models and Contexts
Whenever we discuss a model it’s always within some context. This context can usually be inferred from the set of end-users that use the system. So we have a front-office trading system deployed to traders, or a point-of-sale system used by cashiers in a supermarket. These users relate to the concepts of the model in a particular way, and the terminology of the model makes sense to these users but not necessarily to anyone else outside that context. DDD calls this the bounded context (BC). Every domain model lives in precisely one BC, and a BC contains precisely one domain model.
当我们讨论一个模型的时候,我们总是在某一个上下文中讨论它。 这个上下文通常都可以从使用系统的最终用户群体来推断出来。例如我们针对股票交易员(traders)有部署一个交易所交易系统,我们针对超市的收银员有一个零售系统。这些用户都以特殊的方式来和这些概念产生关系。一些专有的名词对于这些用户来说,是有意义的;而对于上下文边界意外的用户没有意义,也不是必须要理解的事情。DDD把这个东西成为有界上下文(Bounded Context)。每一个领域模型都生活在一个BC中,每一个BC都包含了一个领域模型。
I must admit when I first read about BCs I couldn’t see the point: if BCs are isomorphic to domain models, why introduce a new term? If it were only end-users that interacted with BCs, then perhaps there wouldn’t be any need for this term. However, different systems (BCs) also interact with each other, sending files, passing messages, invoking APIs, etc. If we know there are two BCs interacting with each other, then we know we must take care to translate between the concepts in one domain and those of the other.
不得不承认一开始当我读到BC的时候,我认为毫无意义。如果BCs和领域模型是一致的,那么我们为什么要引入一个新的概念呢。如果仅仅只有最终用户和有界上下文产生了交互,那么也许就不应该有这个概念。然而,不同的系统(BCs)之间也是存在交互的,比如相互发送文件,传递消息,调用API等等。如果我们知道在不同的有界上下文之间有交互,那我们必须小心的翻译这些在不同有界上下文之间传递的东西。
Putting an explicit boundary around a model also means we can start discussing relationships between these BCs. In fact, DDD identifies a whole set of relationships between BCs, so that we can rationalize as to what we should do when we need to link our different BCs together:
同样我们针对一个模型明确的画出一条界限之后,那我们就可以讨论BC之间的关系了。 而实际上DDD命名了非常多不同种类的BC之间的关系,这样当我们需要把不同的BC连接起来的时候,我们就可以采用合理的措施了:
差不多就是下面的关系了:
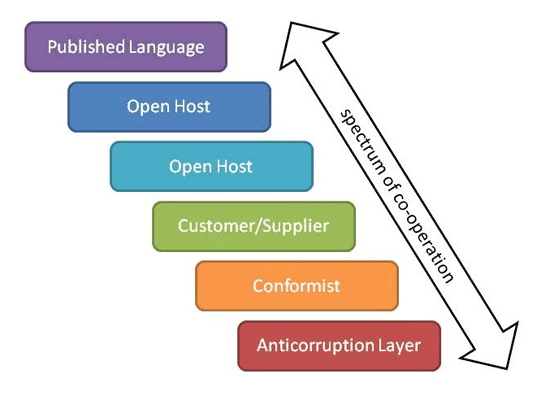
- published language: the interacting BCs agree on a common a language (for example a bunch of XML schemas over an enterprise service bus) by which they can interact with each other;
- open host service: a BC specifies a protocol (for example a RESTful web service) by which any other BC can use its services;
- shared kernel: two BCs use a common kernel of code (for example a library) as a common lingua-franca, but otherwise do their other stuff in their own specific way;
- customer/supplier: one BC uses the services of another and is a stakeholder (customer) of that other BC. As such it can influence the services provided by that BC;
- conformist: one BC uses the services of another but is not a stakeholder to that other BC. As such it uses “as-is” (conforms to) the protocols or APIs provided by that BC;
- anti-corruption layer: one BC uses the services of another and is not a stakeholder, but aims to minimize impact from changes in the BC it depends on by introducing a set of adapters - an anti-corruption layer.
Layers and Hexagons(分层架构和六边形)
Let’s now turn inwards and consider the architecture of our own BC (system). Fundamentally DDD is only really concerned about the domain layer and it doesn’t, actually, have a whole lot to say about the other layers: presentation, application or infrastructure (or persistence layer). But it does expect that they exist. This is the layered architecture pattern (Figure 4).
讨论完毕BC和BC之间的关系之后,我们来向内讨论,讨论我们自己的BC内的架构。从根本上来讲,DDD真正只关心domain layers,而DDD并不真的关心其他的层次,例如:表现层,应用层,基础设施层(持久化层)。尽管DDD不关心这些层,但是DDD还是假设它们存在的:

We’ve been building multi-layer systems for years, of course, but that doesn’t mean we’re necessarily that good at it. Indeed, some of the dominant technologies of the past - yes, EJB 2, I’m looking at you! - have been positively harmful to the idea that a domain model can exist as a meaningful layer. All the business logic seems to seep into the application layer or (even worse) presentation layer, leaving a set of anaemic domain classes [3] as an empty husk of data holders. This is not what DDD is about.
我们构建分层次的系统已经好多年了,但是这并不意味着我们很擅长。事实上,例如EJB2这样过去曾经作为主导的技术,对于领域模型作为实际存在的有意义的一层,产生了非常巨大的伤害。所有的业务逻辑都渗透到了应用层,甚至渗透到了表现层,而剩下的一堆贫血的领域class作为数据的空壳,这并不是DDD所倡导的事情。
So, to be absolutely clear, there shouldn’t be any domain logic in the application layer. Instead, the application layer takes responsibility for such things as transaction management and security. In some architectures it may also take on the responsibility of ensuring that domain objects retrieved from the infrastructure/persistence layer are properly initialized before being interacted with (though I prefer it that the infrastructure layer does this instead).
所以,让我们彻彻底底的说清楚,在application layer中不应该有任何领域逻辑在其中。Application Layer的主要的责任是处理例如事务管理,安全管理这样的事情。在有一些架构中,application layer也承担了领域对象从持久层中被检索和正确的初始化出来。
Where the presentation layer runs in a separate memory space then the application layer also acts as a mediator between the presentation layer and domain layer. The presentation layer generally deals with serializable representations of a domain object or domain objects (data transfer objects, or DTOs), typically one per “view”. If these are modified then the presentation layer sends back any changes to the application layer, which in turn determines the domain objects that have been modified, loads them from the persistence layer, and then forwards on the changes to those domain objects.
对于表现层运行在单独的一个内存空间的这种情况下,application layer也扮演着一个mediator的角色,在表现层和领域层之间。
One downside of the layered architecture is that it suggests a linear stacking of dependencies, from the presentation layer all the way down to the infrastructure layer. However, we may want to support different implementations within both the presentation and infrastructure layer. That’s certainly the case if (as I presume we are!) we want to test our application:
层次化的架构的一个不好之处,在于它引入了一堆线性关系的依赖栈,从表现层一直到持久化层。然而我们可能会希望在表现层和持久化层支持不同的实现方案,例如我们想要测试我们的应用:
- for example, tools such as FitNesse [4] allow us to verify the behaviour of our system from an end-users’ perspective. But these tools don’t generally go through the presentation layer, instead they go directly to the next layer back, the application layer. So in a sense FitNesse acts as an alternative viewer.
- similarly, we may well have more than one persistence implementation. Our production implementation probably uses RDBMS or similar technology, but for testing and prototyping we may have a lightweight implementation (perhaps even in-memory) so we can mock out persistence.
例如如果我们使用一个叫做FitNesse的工具,那就允许我们从end-user的角度来验证我们系统的行为,但是这类工具不会经过我们的所谓的表现层,而它们会直接和下面的一层,也就是application layer进行交互。在这种情况下FitNesse扮演的就是另外一种viewer的角色。
同样的,我们也会希望支持多个持久层的实现。例如我们的生产环境的实现,我们希望使用关系型的数据库。但是对于开发环境或者原型,我们希望使用的是一些轻量级的实现,例如embeded db,这样我们就可以模拟测试持久化层了。
We might also want to distinguish between interactions between the layers that are “internal” and “external”, where by internal I mean an interaction where both layers are wholly within our system (or BC), while an external interaction goes across BCs.
同时我们也想区分内部和外部的一些交互,当我们说内部的时候,我们的意思是全部在我们BC当中的不同layer之间的交互,当我们说external的时候,我们表达的是跨BC的交互。
So rather than consider our application as a set of layers, an alternative is to view it as a hexagon [5], as shown in Figure 5. The viewers used by our end-users, as well as FitNesse testing, use an internal client API (or port), while calls coming in from other BCs (eg RESTful for an open host interaction, or an invocation from an ESB adapter for a published language interaction) hit an external client port. For the back-end infrastructure layer we can see a persistence port for alternative object store implementations, and in addition the objects in our domain layer can call out to other BCs through an external services port.
所以说与其我们把我们的应用当作一系列的层次来考虑,另外一种可选的方案是把它看作六边形。
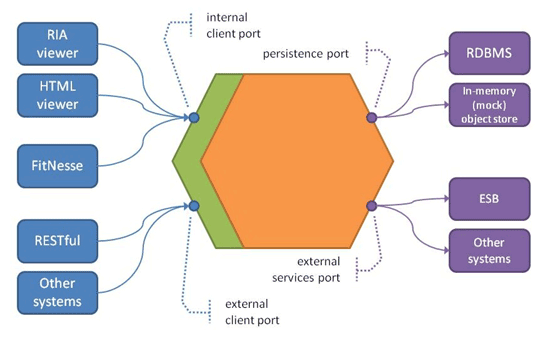
对于我们的真实的用户,还有我们提到的FitNesse测试来说,我们都使用的内部的客户接口(internal client API),来自于其他BC的调用,例如restful的调用,或者企业总线的调用,我们把它们认为是来自于外部的接口 ,当然我们也可以看到对应的persistence port。
Building Blocks
As we’ve already noted, most DDD systems will likely use an OO paradigm. As such many of the building blocks for our domain objects may well be familiar, such as entities, value objects and modules. For example, if you are a Java programmer then it’s safe enough to think of a DDD entity as basically the same thing as a JPA entity (annotated with @Entity); value objects are things like strings, numbers and dates; and a module is a package.
就像我们之前已经提到过的事情,很多DDD系统都很可能使用OO的范式来实现。因此我们提到的很多building blocks对于我们的领域对象来说,都是很熟悉的,例如实体对象,值对象,模块。例如你是一个Java的程序员的话,那么你可以很安全的把DDD entity理解为一个JPA Entity,值对象就是例如String,numbers或者dates之类的东西。而module其实就是一个包。
However, DDD tends to place rather more emphasis on value objects than you might be used to. So, yes, you can use a String to hold the value of a Customer’s givenName property, for example, and that would probably be reasonable. But what about an amount of money, for example the price of a Product? We could use an int or a double, but (even ignoring possible rounding errors) what would 1 or 1.0 mean? $1? €1? ¥1? 1 cent, even? Instead, we should introduce a Money value type, which encapsulates the Currency and any rounding rules (which will be specific to the Currency).
然而DDD更倾向于投入更多的精力在关于值对象,而不是像我们习惯的那样(意思是我们习惯的事情是投入大量的精力在领域实体对象上)。
举个例子我们可以使用一个字符串来承载一个客户的名称的属性,这样也很合理。但是对于金钱来说呢,我们可以使用int或者double类型吗,那么金钱的币种是什么呢。所以这种语言内置的普通的类型就不够用,我们要引入一个新的叫做Money的值类型,这个值类型封装了比重和rounding的规则。
Moreover, value objects should be immutable, and should provide a set of side-effect free functions to manipulate them. We should be able to write:
更进一步,值对象应该是immutable的,并且应该提供一系列的无副作用的函数来操作它们。
Money m1 = new Money("GBP", 10);
Money m2 = new Money("GBP", 20);
Money m3 = m1.add(m2);
Adding m2 to m1 does not alter m1, instead it returns a new Money object (referenced by m3) which represents the two amounts of Money added together.
例如上面的代码中,m1和m2相加,并不会修改m1或者m2的值,而是产生一个新的值。
Values should also have value semantics, which means (in Java and C# for example) that they implement equals() and hashCode(). They are also often serializable, either into a bytestream or perhaps to and from a String format. This is useful when we need to persist them.
值应该有值的语义,对于Java来说也就是实现了equals和hashCode的函数。同时它们应该可以序列化,要么序列化成一个字节流,要么序列化成为一个字符串,这样当我们需要持久化它们的时候,就非常方便了。
Another case where value objects are common is as identifiers. So a (US) SocialSecurityNumber would be a good example, as would a RegistrationNumber for a Vehicle. So would a URL. Because we have overridden equals() and hashCode(), all of these could then safely be used as keys in a hash map.
值对象的另外一个用途,是可以作为一个identifier,例如一个社保号可以唯一的代表一个人,一个车辆注册号可以唯一的代表一辆车,同理一个URL也是唯一的。而且因为我们实现了equals和hashCode所以我们可以很安全的把它们用在一个hashmap中。提到hashmap真心很赞啊,谁用谁知道。
Introducing value objects not only expands our ubiquitous language, it also means we can push behaviors onto the values themselves. So if we decided that Money can never contain negative values, we can implement this check right inside Money, rather than everywhere that a Money is used. If a SocialSecurityNumber had a checksum digit (which is the case in some countries) then the verification of that checksum could be in the value object. And we could ask a URL to validate its format, return its scheme (for example http), or perhaps determine a resource location relative to some other URL.
引入值对象不仅仅扩展了我们的ubiquitous language,同样也代表着我们可以把行为推送给到values本身.例如如果我们决定对于一个Money的对象,不应该有负数的取值,那我们大可以在Money类内部实现这个校验,而不是在所有用到Money的地方来完成这个校验.同理可以类推到社保号,URL之类的东西.
Our other two building blocks probably need less explanation. Entities are typically persisted, typically mutable and (as such) tend to have a lifetime of state changes. In many architectures an entity will be persisted as row in a database table. Modules (packages or namespaces) meanwhile are key to ensuring that the domain model remains decoupled, and does not descend into one big ball of mud [6]. In his book Evans talks about conceptual contours, an elegant phrase to describe how to separate out the main areas of concern of the domain. Modules are the main way in which this separation is realized, along with interfaces to ensure that module dependencies are strictly acyclic. We use techniques such as Uncle “Bob” Martin’s dependency inversion principle [7] to ensure that the dependencies are strictly one-way.
对于另外两种building blocks来说,需要的解释不多.Entities通常都是持久化的,通常都是可变的,并且伴随着它们的生命周期的不同阶段,有不同的状态. Modules同时是一个非常关键的东西,用来保证我们的领域模型是解耦的.
在Evans的书中, 作者使用了概念轮廓这个词来形象的描述了这个概念. Modules是主要的实现解耦的方式.
Entities, values and modules are the core building blocks, but DDD also has some further building blocks that will be less familiar. Let’s look at these now.
Aggregates and Aggregate Roots(聚合与聚合根)
If you are versed in UML then you’ll remember that it allows us to model an association between two objects either as a simple association, as an aggregation, or using composition. An aggregate root (sometimes abbreviated to AR) is an entity that composes other entities (as well as its own values) by composition. That is, aggregated entities are referenced only by the root (perhaps transitively), and may not be (permanently) referenced by any objects outside the aggregate. Put another way, if an entity has a reference to another entity, then the referenced entity must either be within the same aggregate, or be the root of some other aggregate.
如果你精通UML的话,那么你会记得它允许我们把2个对象之间的关系建模为一个简单的association,一个aggregation,或者是一个composition。
一个聚合根(有的时候也被简称为AR)是一个实体组合了其他的实体(当然它本身也拥有values)通过composition的方式。也就是说被聚合的实体仅被root所引用(当然有可能是transitively,也就是间接的传递式的引用),而且也不能(永久性的)被任何其他的不在同一个聚合的实体所引用。
让我们换一种说法,如果一个实体A拥有另外一个实体B的引用,那么被引用的实体B要么在同一个聚合里面,要么是作为另外一个聚合的根。
Many entities are aggregate roots and contain no other entities. This is especially true for entities that are immutable (equivalent to reference or static data in a database). Examples might include Country, VehicleModel, TaxRate, Category, BookTitle and so on.
非常多实体是聚合根,而且不包含其他实体。这种特性对于不可变的实体来说,特别的正确。具体的例子,我们可以看 Country, VehicleModel, TaxRate, Category, BookTitle等等
However, more complex mutable (transactional) entities do benefit when modelled as aggregates, primarily by reducing the conceptual overhead. Rather than having to think about every entity we can think only of the aggregate roots; aggregated entities are merely the “inner workings” of the aggregate. They also simplify the interactions between entities; we follow the rule that (persisted) references may only be to an aggregate’s root, not to any other entities within the aggregate.
然而,对于更多的更复杂的可变(事务型)的实体来说,把它们建模为聚合根是有很大的好处的,主要的好处是减少对于概念理解上的开销(Conceptual Overhead[99])。我们的复杂系统中,有非常多的实体,当我们把这些实体建模为聚合的时候,我们就不用在同一时刻处理和思考所有的实体,我们仅仅思考聚合根就可以了,而那些被聚合的实体仅仅是聚合的内部工作了。通过聚合根,我们实现了系统的抽象。同时使用聚合我们也大大简化了实体之间的交互。
Another DDD principle is that an aggregate root is responsible for ensuring that the aggregated entities are always in a valid state. For example, an Order (root) might contain a collection of OrderItems (aggregated). There could be a rule that any OrderItem cannot be updated once the Order has been shipped. Or, if two OrderItems refer to the same Product and with the same shipping requirements, then they are merged into the same OrderItem. Or, an Order’s derived totalPrice attribute should be the sum of the prices of the OrderItems. Maintaining these invariants is the responsibility of the root.
另外一个DDD的原则是聚合根的职责是保证被聚合的实体总是处于一个有效的状态。例如,一个Order(作为一个聚合根)可能包含了一系列的OrderItems(被聚合)。我们可能有一个业务规则说,任何已经被发货的订单(Order)中的商品(OrderItem)的信息都不能被更新。当然我们也可能有另外一个规则来说,如果2个OrderItems指的的同一个商品,并且有相同的发货的需求的话,那它们应该被合并到同一个OrderItem中。或者我们有另外一个业务规则说,一个订单(Order)的推导出来的价格属性,应该是所有的OrderItems的价格之和。维护这些 invariant(明明是变量,为什么要用这个不变量的词呢)是作为聚合根的职责。
However … it is only feasible for an aggregate root to maintain invariants between objects entirely within the aggregate. The Product referenced by an OrderItem would almost certainly not be in the AR, because there are other use cases which need to interact with Product independently of whether there is an Order for it. So, if there were a rule that an Order cannot be placed against a discontinued Product, then the Order would need to deal with this somehow. In practical terms this generally means using isolation level 2 or 3 to “lock” the Product while the Order is updated transactionally. Alternatively, an out-of-band process can be used to reconcile any breakage of cross-aggregate invariants.
然而,在一个聚合中,只有聚合root才是最合适的用来在不同的objects之间来维护invariants的角色。让我们来试想以下,对于一个OrderItem来说,它引用了Product,肯定是不适合作为AR(Aggregate Root)的,因为还存在其他的用例(use cases)需要和Product进行交互,无论是否存在一个Order,因为OrderItem依赖的是Order的存在,所以当Order不存在的时候,也就没有OrderItem,所以用OrderItem来当聚合根是不合适的。假设我们有一个规则说,针对一个已经停产的产品来说,不能下Order,那么这其实是Order的职责来处理这个业务规则。在更实际的情况下,这个意思就是说,我们需要使用level 2 or 3级别的锁,当我们来更新订单的时候。
当然可选的是,我们可以拥有一个out-of-band(额外)的流程来调和(reconcile)任何跨聚合根的breakage(不一致性,错误性。)看来这个out-of-band的东西还是挺重要的,因为不是所有的人都会严格的遵守聚合根的逻辑,当然有的时候我们设计聚合根的经验不足,可能也会设计出来一些有问题的方案,必须要使用这种额外的调和的手段。
Stepping back a little before we move on, we can see that we have a spectrum of granularity:
现在我们来看以下粒度大小的光谱:
value < entity < aggregate < module < bounded context
Repositories
In enterprise applications entities are typically persisted, with values representing the state of those entities. But how do we get hold of an entity from the persistence store in the first place?
在企业应用中实体通常是持久化存储的,实体的值代表了实体的状态。但是我们一开始是怎么从持久化的存储中获得一个实体的呢?
A repository is an abstraction over the persistence store, returning entities - or more precisely aggregate roots - meeting some criteria. For example, a customer repository would return Customer aggregate root entities, and an order repository would return Orders (along with their OrderItems). Typically there is one repository per aggregate root.
repository是在持久化存储上的一层抽象,用来返回满足特定条件的实体,或者更准确的说,聚合根。例如一个customer repository可以返回客户的聚合根实体,一个订单(Order) Repository可以返回订单的聚合根。通常来说,针对每一个聚合根就有一个repository。
Because we generally want to support multiple implementations of the persistence store, a repository typically consists of an interface (eg CustomerRepository) with different implementations for the different persistence store implementations (eg CustomerRepositoryHibernate, or CustomerRepositoryInMemory). Because this interface returns entities (part of the domain layer), the interface itself is also part of the domain layer. The implementations of the interface (coupled as they are to some specific persistence implementation) are part of the infrastructure layer.
因为通常我们希望支持持久化仓库的多种不同的实现,所以我们通常会实现一个repository的interface,同步的我们会针对这个interface来针对不同的持久化仓库来做出不同的实现。因为这个接口本身返回实体(entity是领域层的一部分),所以这个repository interface本身也是领域层的一部分。但是针对interface的实现(因为和特定的持久化基础设施相耦合了)它们算是infrastructure层的一部分。
Often the criteria we are searching for is implicit in the method name called. So CustomerRepository might provide a findByLastName(String) method to return Customer entities with the specified last name. Or we could have an OrderRepository to return Orders, with a findByOrderNum(OrderNum) returning the Order matching the OrderNum (note the use of a value type here, by the way!).
通常我们的查询条件都是隐式的(隐含在method name中)。所以我们的Customer Repository中可能提供了一个叫做findByLastName的方法来返回特定拥有指定last name的实体。或者我们肯恶搞有一个Order Repository用来返回Orders,这个Repository可能有一个findByOrderNum的方法来返回执行的订单号码。
More elaborate designs wrap the criteria into a query or a specification, something like findBy(Query< T >), where Query holds an abstract syntax tree describing the criteria. The different implementations then unwrap the Query to determine how to locate the entities meeting the criteria in their own specific way.
更缜密(elaborate)的设计方式是把查询条件封装到一个query或者specification中,如果这样做的话,我们的Repository的查询方法可能就长得像这样了 findBy(Query< T >)了,这里的Query或者Specification内具备一个描述查询条件的抽象的语法树。然后不同的持久化框架可以unwrap这个Query的实现,然后针对不同的持久化实现来使用不同的查询方法。
A variation on using specific repository interfaces per aggregate root is to use generic repositories, such as Repository< Customer >. This provides a common set of methods, such as findById(int) for every entity. This works well when using Query< T > (eg Query< Customer >) objects to specify the criteria. For the Java platform there are also frameworks such as Hades [9] that allow a mix-and-match approach (start with generic implementations, and then add in custom interfaces as and when are needed).
每一个聚合根对应一个指定的repository interface的方式,其实还有另外一种变种,例如 Repository< Customer >。在这种方式下,提供了一系列的通用的方法的集合,例如 findById(int) 的方法针对每一个实体都是适用的。这种模式在配合使用查询条件对象来指定查询条件的时候可以work的非常好。例如对于Java平台来说,有Hades这样的框架,允许mix-and-match的方式来完成通用的实现,然后增加一些定制化的接口。
Repositories aren’t the only way to bring in objects from the persistence layer. If using an object-relational mapping (ORM) tool such as Hibernate we can navigate references between entities, allowing us to transparently walk the graph. As a rule of thumb references to the aggregate roots of other entities should be lazy loaded, while aggregated entities within an aggregate should be eagerly loaded. But as ever with ORMs, expect to do some tuning in order to obtain suitable performance characteristics for your most critical use cases.
Repositories并不是唯一的把对象从持久化层拿出来的方式。如果我们使用一个ORM工具,例如Hibernate,的话,我们可以在实体之间浏览引用关系,也允许我们透明地在图(Graph of entities)之间浏览不同的实体。根据我们的经验来看,从别的实体到聚合根的引用,应该采用懒加载模式;而针对一个聚合内部的被聚合的实体应该被积极的加载(懒加载的反义词,暂时没找到特别贴切的词)。但是对于特定的ORMs来说,还应该考虑特性的参数调优,以便对于critical use cases的性能是满足要求的。
In most designs repositories are also used to save new instances, and to update or delete existing instances. If the underlying persistence technology supports it then these may well live on a generic repository, though … from a method signature point of view there’s nothing really to distinguish saving a new Customer from saving a new Order.
在大多数的repositories的设计中,repositories也被用来保存新的实例,更新或者删除存在的实例。后面半句话,看不到表达的精髓点,无意思。
One final point on this… it’s quite rare to create new aggregate roots directly. Instead they tend to be created by other aggregate roots. An Order is a good example: it would probably be created by invoking an action by the Customer.
我们最后要表达的一个点是,直接创建一个聚合根的对象是很罕见的。实际上一个聚合根的对象,往往是被其他聚合根所创建的。Order就是一个很好的例子:它很可能是被Customer对象的一个动作创建出来的。
Factories
If we ask an Order to create an OrderItem, then (because after all the OrderItem is part of its aggregate) it’s reasonable for the Order to know the concrete class of OrderItem to instantiate. In fact, it’s reasonable for an entity to know the concrete class of any entity within the same module (namespace or package) that it needs to instantiate.
如果我们让一个Order对象创建一个OrderItem,那么(因为归根结底所有的OrderItem都是它的聚合),对于Order来说知晓OrderItem的concrete class是很合理的,因为它需要去实例化一个OrderItem。事实上,让一个实体知晓任何一个它需要初始化的实体的concrete class这件事,只要它们在同一个module(package or namespace)中,就是很合理的。
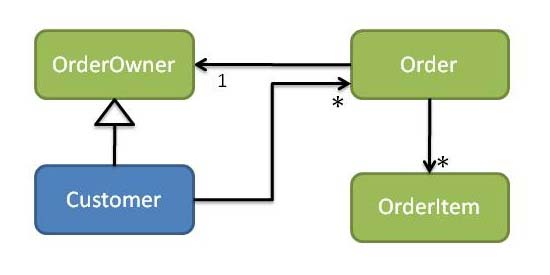
Suppose though that the Customer creates an Order, using the Customer’s placeOrder action (see Figure 6). If the Customer knows the concrete class of Order, that means that the customer module is dependent on the order module. If the Order has a back-reference to the Customer then we will get a cyclic dependency between the two modules.
假设Customer类创建了一个Order的对象,使用的是Customer类的placeOrder的动作。如果Customer类知道了Order的concrete class的话,那就意味着customer module是依赖于order module的。如果订单(Order)本身拥有一个反向的引用到Customer,那么我们就会获得一个循环的依赖,在这两个模块之间。
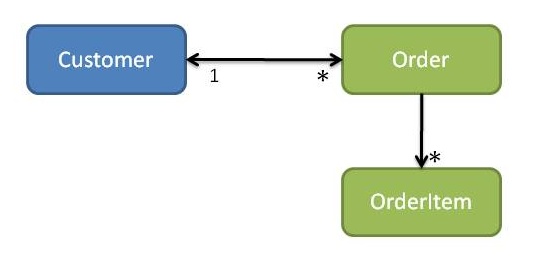
Figure 6:Customer and Orders(Cyclic dependencies)
As already mentioned, we can use the dependency inversion principle to resolve this sort of thing: to remove the dependency from order -> customer module we would introduce an OrderOwner interface, make Order reference an OrderOwner, and make Customer implement OrderOwner (see Figure 7).
就像我们曾经提到过的,我们可以使用DI(dependency inversion)依赖反转原理来解决这个问题:为了移除从 order 到 customer 模块的依赖,我们可以引入一个OrderOwner的接口,让Order 引用一个OrderOwner,然后让Customer类实现OrderOwner的接口。[98] 下图中,OrderOwner是一个interface。
What about the other way, though: if we wanted order -> customer? In this case there would need to be an interface representing Order in the customer module (this being the return type of Customer’s placeOrder action). The order module would then provide implementations of Order. Since customer cannot depend on order, it instead must define an OrderFactory interface. The order module then provides an implementation of OrderFactory in turn (see Figure 8).
我们来考虑一下另外一个方式:如果我们希望 order -> customers,在这个例子中那就应该有一个interface代表着Order,这个interface应该在customer module中(因为这个interface就是Customer的placeOrder函数返回的数据类型)。然后我们的Order module中应该提供针对Order 这个interface的实现。因为customer类不能够依赖于order,那么在Order module中则相应的应该定义一个OrderFactory的interface;同理我们在Order Module中针对Order interface提供一个实现。具体图示如下:
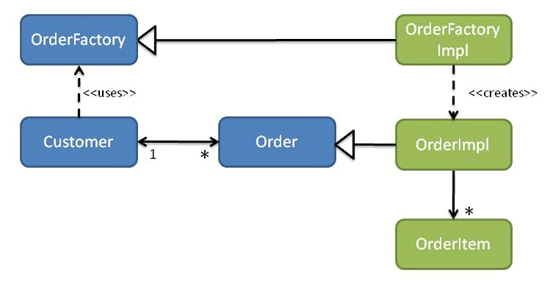
There might also be a corresponding repository interface. For example, if a Customer could have many thousands of Orders then we might remove its orders collection. Instead the Customer would use an OrderRepository to locate (a subset of) its Orders as required. Alternatively (as some prefer) you can avoid the explicit dependency from an entity to a repository by moving the call to the repository into a higher layer of the application architecture, such as a domain service or perhaps an application service.
当然可能还有一个对应的repository interface。例如,如果一个Customer可以有非常多的Orders,然后我们也可能会移除这个客户的订单集合。Customer类可以使用一个OrderRepository来定位它的需要的订单;当然作为替代的方案,你可以避免显式的从一个实体到一个repository的依赖,而把对于repository的调用转移到application architecture的更高层次上,例如domain service层或者是application service。
Indeed, services are the next topic we need to explore. 而关于什么是services正好是我们下一节要谈到的话题。
Domain services, Infrastructure services and Application services
A domain service is one which is defined within the domain layer, though the implementation may be part of the infrastructure layer. A repository is a domain service whose implementation is indeed in the infrastructure layer, while a factory is also a domain service whose implementation is generally within the domain layer. In particular both repositories and factories are defined within the appropriate module: CustomerRepository is in the customer module, and so on.
一个domain服务是定义在domain layer的服务,因为可能domain服务的实现有可能是infrastructure layer。一个repository是一个领域服务,它的实现确实是术语infrastructure layer的,然而一个factory也是一个领域服务但是它的实现通常来说都是在domain layer的。更特别的是说,repositories和factories都是定义在合适的module中的。例如CustomerRepository这个接口,是定义在customer这个module中的,具体的实现可能在别的地方。
More generally though a domain service is any business logic that does not easily live within an entity. Evans suggests a transfer service between two bank accounts, though I’m not sure that’s the best example (I would model a Transfer itself as an entity). But another variety of domain service is one that acts as a proxy to some other bounded context. For example, we might want to integrate with a General Ledger system that exposes an open host service. We can define a service that exposes the functionality that we need, so that our application can post entries to the general ledger. These services sometimes define their own entities which may be persisted; these entities in effect shadow the salient information held remotely in the other BC.
更一般而言,domain service是任何业务逻辑,这些业务逻辑并不简单的存在与一个实体(entity)中。 Evans在书中举了个例子,transfer在两个银行账户之间,尽管我不太确定这是最好的例子。@todo **看来还是跑不掉啊,要理解DDD的精髓,还是需要详细的去看DDD的原书的。这也证明了一句话,从大师本身学习,而不是从大师的学生们学习。 domain service的另外一个变种是作为一个代理(proxy)到其他的有界上下文。例如我们可能想要和一个总账系统(General Ledger System)集成,这个总账系统采用Open Host service的方式对外暴漏交互方式。我们可以定义一个service来暴露我们需要的功能,这样我们的应用就可以发送记录到这个总账系统了。这些服务有的时候会定义它们自己的实体,甚至这些实体可能被持久化;这些实体实际上掩藏掉了远端的有界上下文的显著的特性。
We can also get services that are more technical in nature, for example sending out an email or SMS text message, or converting a Correspondence entity into a PDF, or stamping the generated PDF with a barcode. Again the interface is defined in the domain layer, but the implementation is very definitely in the infrastructure layer. Because the interface for these very technical services is often defined in terms of simple value types (not entities), I tend to use the term infrastructure service rather than domain service. But you could think of them if you want as a bridge over to an “email” BC or an “SMS” BC if you wanted to.
我们也可以找到一些在本质上是技术特性的服务,例如我们要发送出去一个邮件或者SMS消息,或者是把一个对应的entity转换为一个PDF文件,或者是在生成的PDF文件上添加一个二维码。再一次,我们强调这个interface是定义在domain layer的,但是这个interface的具体实现确确实实的存在与infrastructure layer的。因为这一类的服务的接口,通常都是采用simple value type来进行定义的,所以我经常习惯性叫它们 infrastructure service而不是domain service。但是你可以把它们想象成为在我们的application BC与 email BC或者是SMS BC之间的桥梁。
While a domain service can both call or be called by a domain entity, an application service sits above the domain layer so cannot be called by entities within the domain layer, only the other way around. Put another way, the application layer (of our layered architecture) can be thought of as a set of (stateless) application services.
一个domain service既可以调用一个domain entity也可以被一个domain entity调用,但是一个application service是位于domain layer层之上的一层,所以应用服务不可以被domain layer的实体调用。让我们换一种讲法,application layer可以被看做(无状态)的应用服务的集合。
As already discussed, application services usually handle cross-cutting concerns such as transactions and security. They may also mediate with the presentation layer, by: unmarshalling the inbound request; using a domain service (repository or factory) to obtain a reference to the aggregate root being interacted with; invoking the appropriate operation on that aggregate root; and marshalling the results back to the presentation layer.
就像已经讨论的,应用服务经常被用来处理cross-cutting concerns,这个名词在我之前的Spring的笔记中有提到,例如事务处理或者是安全。应用服务通常也扮演者与展现层的中间层的角色,例如应用可以可以解构输入请求,使用一个domain service来获得一个聚合根并与之发生交互。或者是调用聚合根上一个适合的操作,当然也包括构造请求的返回值并且发送会到展现层。
I should also point out that in some architectures application services call infrastructure services. So, rather than an entity call a PdfGenerationService to convert itself to a PDF, the application service may call the PdfGenerationService directly, passing information that it has extracted from the entity. This isn’t my particular preference, but it is a common design. I’ll talk about this more shortly.
当然必须指出的是,在某一些架构中,应用服务是会直接调用infrastructure layer的服务的。所以应用层服务可能会直接调用 PdfGenerationService,并且传递从领域实体中抽取的数据,而不是一个领域实体调用PDF生成服务,并且把自己转换为PDF文件。虽然这不是我喜欢的设计模式,但是这种设计模式是非常常见的。我们稍后再聊。
Okay, that completes our overview of the main DDD patterns. There’s plenty more in Evans 500+page book - and it’s well worth the read - but what I’d like to do next is highlight some areas where people seem to struggle to apply DDD.
到此为止,我们讲完了主要的DDD pattern。Evans的书有500多页,非常值得一读,但是我想要做的事情仅仅是指出其中大家最容易犯错的地方。
Problems and Hurdles (问题与障碍)
Enforcing a layered architecture (确保分层的架构)
Here’s the first thing: it can be difficult to strictly enforce the architectural layering. In particular, the seeping of business logic from the domain layer into the application layer can be particularly insidious.
这是我们要说的第一件事情,就是严格的确保一个分层的架构是非常困难的事情。特别的是,有一些业务逻辑会在不知不觉中渗透到应用服务层。
I’ve already singled out Java’s EJB2 as a culprit here, but poor implementations of the model-view-controller pattern can also cause this to happen. What happens is the controller (= application layer), takes on far too much responsibility, leaving the model (= domain layer) to become anaemic. In fact, there are newer web frameworks out there (in the Java world, Wicket [10] is one up-and-coming example) that explicitly avoid the MVC pattern for this sort of reason.
我已经单独批评过EJB2的模式了,但是实现的比较差的MVC的设计模式,也经常会导致这个问题的发生。最常见的就是controller类(本应该是application layer的类)承担了太多的职责,让领域的模型变得贫血。实际上,有一些新的web框架的出现,明确的别面了MVC的设计模式的使用,仅仅就是因为这个原因。
Presentation layer obscuring the domain layer
表现层遮盖了领域层。
Another issue is trying to develop a ubiquitous language. It’s natural for domain experts to talk in terms of screens, because, after all, that is all that they can see of the system. Asking them to look behind the screens and express their problem in terms of the domain concepts can be very difficult.
这个问题主要是在我们在发展一套ubiquitous语言的时候,对于领域专家来说他们会非常自然的使用电脑显示屏上的东西来表达,毕竟屏幕上的东西这是领域专家可以直接从系统中看到的东西。而我们让领域专家透过屏幕,看到阵阵的领域的概念,并且使用领域的concept来表达问题,这个事情是非常困难的。
The presentation layer itself can also be problematic, because a custom presentation layer may not accurately reflect (could distort) the underlying domain concepts and so compromises our ubiquitous language. Even if that isn’t the case, there’s also just the time it takes to put together a user interface. Using agile terminology, the reduced velocity means less progress is made per iteration, and so fewer insights are made into the domain overall.
同时表现层本身也是很容易充满问题的,因为一个客户的表现层可能不能准确的表达和反应下层的领域模型的概念,所以这样表现层就混淆了我们的ubiquitous language。即使表现层准确的表达了下面的领域模型,把领域模型和表现层结合起来也是相当花时间的。使用敏捷的专业术语来说呢,就是我们在每一个迭代中都降低了我们的速度所以我们的进展也非常缓慢,所以随着迭代的进展我们对于domain的insights也是很少的。
The implementation of the repository pattern
On a more technical note, newbies also sometimes seem to get confused separating out the interface of a repository (in the domain layer) from its implementation (in the infrastructure layer). I’m not exactly sure why this is the case: it’s a pretty simple OO pattern, after all. I think it might be because Evans book just doesn’t go down to this level of detail, and that leaves some people high and dry. But it’s also possibly because the idea of substituting out the persistence implementation (as per the hexagonal architecture) is not that widespread, giving rise to systems where persistence implementation has bled into the domain layer.
对于一个更技术化的注意点来说,新人们经常会把一个repository的interface和它的实现弄混淆,interface是在domain layer的,但是它的实现是在infrastructure layer的。我不确定为什么会出现这个问题,这明明是一个很简单的OO设计模式。我认为可能是Evans的书比较high,并没有深入到细节中,这就让很多新人在读完书之后依然是high和dry。当然也有可能是因为 替换持久实现层的想法并没有广泛的传播开,让一些持久化的实现层入侵到了领域层。
The implementation of the service dependencies (服务依赖的实现)
Another technical concern - and where there can be disagreement between DDD practitioners - is in terms of the relationship between entities and domain/infrastructure services (including repositories and factories). Some take the view that entities should not depend on domain services at all, but if that’s the case then it falls to the outer application services to interact with the domain services and pass the results into the domain entities. To my way of thinking this moves us towards having an anaemic domain model.
另外一个技术关注点,可能在不同的DDD使用者之间会有分歧,这个点就是entity与domain service、application service之间的关系。有些人持有一种观点认为:eneity完全不应该依赖于domain service,如果是这样的话,那就只能让application service来和domain service来进行交互了,并且把交互的结果传递会domain entity中。从我看来,这回进一步导致贫血的领域模型。
A slightly softer viewpoint is that entities can depend on domain services, but the application service should pass them in as needed, for example as an argument to an operation. I’m not a fan of this either: to me it is exposing implementation details out to the application layer (“this entity needs such-and-such a service in order to fulfil this operation”). But many practitioners are happy with this approach.
一种稍微缓和一些的观点认为,领域entity可以依赖于domain service,但是应该有application service来传递领域服务需要的东西,例如把一个参数传递给一个operation。我也不赞同这种做法,对于我来看,我认为这是把实现层的细节直接暴漏给了应用服务层。但是很多实践者很喜欢这种approach。
My own preferred option is to inject services into entities, using dependency injection. Entities can declare their dependencies and then the infrastructure layer (eg Hibernate, Spring or some other framework) can inject the services into the entities:
我自己比较喜欢的方式是把服务注入(Inject)到实体中,使用依赖注入(dependency injection)。例如Entity可以声明它们的依赖,并且由infrastructure layer例如Hibernate,Spring等等框架把领域实体的依赖的服务注入到它们中:例如针对下面的代码,我们显式的声明了我们的依赖,应该就是一个OrderFactory的接口。由Spring的框架来注入一个OrderFactory的实现。
public class Customer {
...
private OrderFactory orderFactory;
public void setOrderFactory(OrderFactory orderFactory) {
this.orderFactory = orderFactory;
}
...
public Order placeOrder( ... ) {
Order order = orderFactory.createOrder();
...
return order;
}
}
One alternative is to use the service locator pattern. All services are registered, for example into JNDI, and then each domain object looks up the services it requires. To my mind this introduces a dependency on the runtime environment. However, compared to dependency injection it has lower memory requirements on entities, and that could be a deciding factor.
除了使用Spring这种框架来实现DI,另外一种可选的方式是使用service locator模式。所有的服务都被注册了,例如注册到一个JNDI中(感叹一下,微服务不也有自己的服务注册与服务发现中心吗),然后每一个领域对象自己去找到这个服务来获取自己需要的服务。从我看来这引入了一个新的对于运行时的依赖,而然相比于依赖注入来说,这种模式有更低的内存消耗,这可能是比较决定性的因素。
Inappropriate modularity
不合适的模块粒度。
As we’ve already identified, DDD distinguishes several different levels of granularity over and above entities, namely aggregates, modules and BCs. Getting the right levels of modularization right takes some practice. Just as an RDBMS schema may be denormalized, so too can a system not have modularity (becomes a big ball of mud). But an overnormalized RDBMS schema - where a single entity is broken out over multiple tables - can also be harmful, and so too can an overmodularized system, because it then becomes difficult to understand how the system works as a whole.
就像我们前面指出的,DDD区分不同层级的粒度,例如entity,聚合,modules还有有界上下文(BC)。选择正确的模块化的粒度需要很多实践和经验。就像有的关系数据库不够规范化,我们设计的系统可能也不够模块化,成为一个大泥潭。当然过分的规范化或者模块化也是非常有害的。
中间的话太多,我们摘抄最后一段,比较有意
In practical terms, a typical module (and this is very rough and ready) might contain a half-dozen aggregates, each of which might contain between one entity and several. Of these half-dozen, a good number may well be immutable “reference data” classes. Remember also that the reason we modularize is so that we can understand a single thing (at a certain level of granularity). So do remember that the typical person can only keep in their head between 5 and 9 things at a time [11].
从实践的角度来看,一个典型的module可以包含6个左右的聚合,每一个聚合可以包含一个或者多个实体。在这6个聚合中,相当多的聚合是immutable的。请记住我们要模块话的原因很简单,那就是我们可以理解一个东西。一个典型的人可以在它们的脑袋中记住5到9个东西,这是人类的局限。
好的,终于看完了,有了初步的了解了,后面可以快速的看DDD的原书了,下面是一些引用
Appendix
[1] Domain Driven Design Community http://domaindrivendesign.org/
[2] Spring BeanDoc http://spring-beandoc.sourceforge.net/
[3] Anaemic Domain Model, Martin Fowler http://martinfowler.com/bliki/AnemicDomainModel.html
[4] FitNesse http://fitnesse.org
[5] Hexagonal Architecture, Alistair Cockburn http://alistair.cockburn.us/Hexagonal+architecture
[6] Big Ball of Mud,> Brian Foote & Joseph Yoder http://www.laputan.org/mud/
[7] Dependency Inversion Principle, Robert Martin http://www.objectmentor.com/resources/articles/dip.pdf
[8] LINQ http://msdn.microsoft.com/en-us/netframework/aa904594.aspx
[9] Hades http://hades.synyx.org/
[10] Apache Wicket Web Framework http://wicket.apache.org
[11] Magical Number Seven, ±2 Magic Number Seven
[99]. 在看到这个概念理解上的开销的时候,conceptual overhead的时候,一开始我没懂这是什么意思,但是读到第三遍的时候,我突然懂了,因为我突然明白了,因为联想到了另外一本书《面向对象分析与设计》——< Object-Oriented Analysis and Desgin with Applicaitons>,里面也提到了复杂系统的5个属性。作者认为复杂系统具有:层次结构,相对本源,分离关注,共同模式,稳定的中间态。因为我们要做的很多系统,都是复杂系统,所以在处理这种复杂性时候,人类的能力是有局限的,经过心理学家Miller的研究,人类同时处理的最大信息数量是7个。所以如果我们不做层次化的抽象的话,我们其实是没有办法做复杂系统设计的,因为我们压根理解不了这个复杂系统。
[98]. 关于DI,这里提到的是依赖的反转,Dependency Inversion和我之前看Spring Framework的时候的DI(Dependency Injection)还是不太一样的。这里关于依赖反转的讲解,看到一篇中文博文比较靠谱:
还有一篇英文博客比较靠谱:
Dependency Inversion Principle
英文的首先摘抄一下: In object-oriented design, the dependency inversion principle is a specific form of decoupling software modules. When following this principle, the conventional dependency relationships established from high-level, policy-setting modules to low-level, dependency modules are reversed, thus rendering high-level modules independent of the low-level module implementation details. The principle states:
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g. interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
在OOD中,依赖反转的原理是一种解耦软件模块的特定的方式。当我们遵从这个原理的时候,那些传统的从high-level——策略设定的模块 到 low-level——依赖模块的的关系将被反转,因此将会使得高层级的模块独立于底层级的模块的具体实现,这个原理详细是这么说的:
- 高层级的模块不应该依赖于底层及的模块。它们俩都应该依赖于抽象(例如:interfaces)
- 抽象不应该依赖于细节。细节(Concrete implementations)应该依赖于抽象。
这一片英文的博客写的非常经典,值得翻译一下,这里留一个待办吧。 @todo
tags: Domain-Driven Design